在程序设计中,设计良好的缓存可以避免无意义的重复计算,节省可观的计算资源,从而提高性能。
本文主要关注如何设计一个良好运行,线程安全的缓存方案。
简单实现 一个简单缓存方案的实现如下:
1 2 3 4 5 6 7 IF value in cached THEN return value from cache ELSE compute value save value in cache return value END IF
我们将上面的实现应用到一个简单的示例中:斐波那契序列求值,这是一个很好的缓存应用示例。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 import java.util.HashMap;import java.util.Map;public class NaiveCacheExample { private Map<Long, Long> cache = new HashMap <>(); public NaiveCacheExample () { cache.put(0L , 1L ); cache.put(1L , 1L ); } public Long getNumber (long index) { if (cache.containsKey(index)) { return cache.get(index); } long value = getNumber(index - 1 ) + getNumber(index - 2 ); cache.put(index, value); return value; } }
上面的实现中,使用 Map 来缓存中间结果,序列索引作为 key, 序列值作为 value。
非线程安全
这个问题可以通过使用并发版本的 Map 来缓解,比如 ConcurrentMap。另外,也可以通过各种锁来限制 Map 的访问控制。各自权衡,不做评论
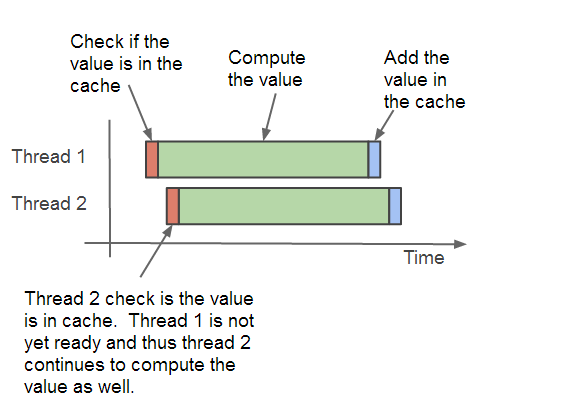
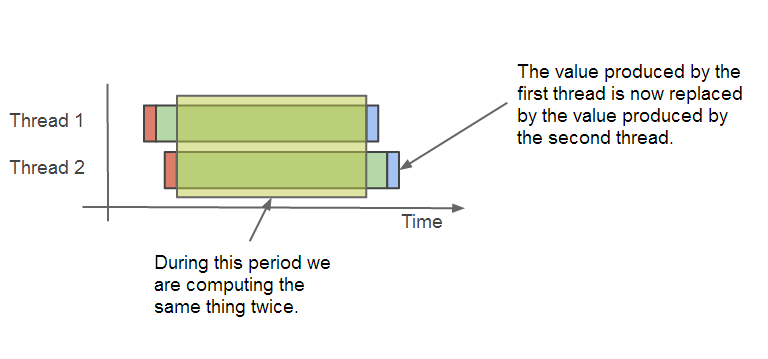
同一个序列值可能被重复计算
假如两个线程需要获取一个相同的序列值,但是这个序列值并不在缓存里面, 此时,这两个线程都会各自去计算这个序列值,从而导致这个序列值被计算了两次。
这种设计难以移植到其他场景应用中
这个缓存方案被硬编码为针对单一计算的实现,在此例中,是斐波那契生成器。
一个改进的设计方案是使用 Callable 和 Future 来实现,加上上文已经提到使用 ConcurrentMap 来缓存值。这三个类可以解决刚刚讨论的缺陷:
ConcurrentMap 的 putIfAbsent() 使用线程安全的方式将一个不在 map 内的新值添加到 map 内。
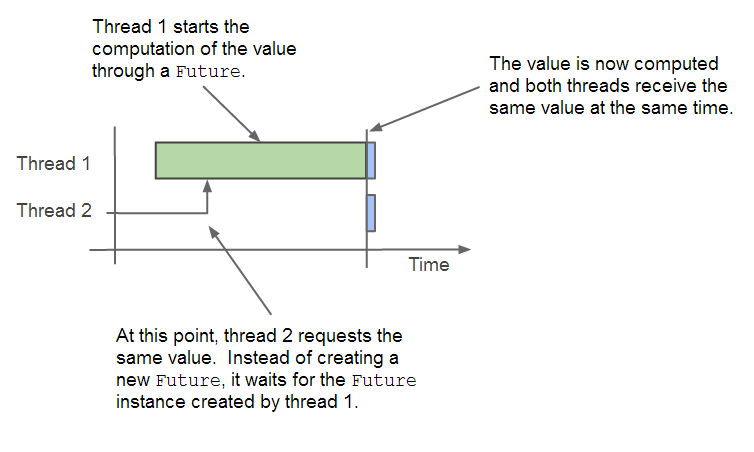
Future 的 get() 方法保证了同时只会有一个线程在计算某个序列值。
最后,求值算法被抽象为 Callable,由于 Callable 可以任意实现,缓存方案就可以应用到任意场景。
线程安全的通用缓存方案 为了将上面的简单缓存实现改造为线程安全并通用的实现,需要进行三处改动:
缓存必须线程安全
足够智能,当第一个线程还没有完成计算时,要避免第二个线程进行相同的计算。当第一个线程完成计算之后,第二个线程直接使用第一个线程计算得来的结果。
将与斐波那契计算相关的代码全部挪出缓存,同时,使用泛型来适应不同的场景。
新版本实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 import java.util.concurrent.Callable;import java.util.concurrent.ConcurrentHashMap;import java.util.concurrent.ConcurrentMap;import java.util.concurrent.ExecutionException;import java.util.concurrent.Future;import java.util.concurrent.FutureTask;public class GenericCacheExample <K, V> { private final ConcurrentMap<K, Future<V>> cache = new ConcurrentHashMap <>(); private Future<V> createFutureIfAbsent (final K key, final Callable<V> callable) { Future<V> future = cache.get(key); if (future == null ) { final FutureTask<V> futureTask = new FutureTask <V>(callable); future = cache.putIfAbsent(key, futureTask); if (future == null ) { future = futureTask; futureTask.run(); } } return future; } public V getValue (final K key, final Callable<V> callable) throws InterruptedException, ExecutionException { try { final Future<V> future = createFutureIfAbsent(key, callable); return future.get(); } catch (final InterruptedException e) { cache.remove(key); throw e; } catch (final ExecutionException e) { cache.remove(key); throw e; } catch (final RuntimeException e) { cache.remove(key); throw e; } } public void setValueIfAbsent (final K key, final V value) { createFutureIfAbsent(key, new Callable <V>() { @Override public V call () throws Exception { return value; } }); } }
这个实现尚不足 55 行,却满足上述所有的需求。我们逐一分析:
第一, 泛型参数 K 表示键类型,V 表示值类型,在斐波那契的例子中,K 和 V 都是 Long。
第二,缓存值都保存在 ConcurrentMap 而不是单纯的 Map 中。更重要的是, cache 中的保存值不是直接的 V 类型值,而是 Future,这种方式是避免重复计算的关键。
第三,不论有多少个线程使用到了缓存,我们都需要保证一个 key 只有添加一个对应的 Future,下面的代码实现了这个目的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 private Future<V> createFutureIfAbsent (final K key, final Callable<V> callable) { Future<V> future = cache.get(key); if (future == null ) { final FutureTask<V> futureTask = new FutureTask <V>(callable); future = cache.putIfAbsent(key, futureTask); if (future == null ) { future = futureTask; futureTask.run(); } } return future; }
只需要执行 FutureTask 一次,其他线程等待获取值即可,这是避免重复计算的关键。
第四,从 Future 获取最终需要用到的值,Future#get()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public V getValue (final K key, final Callable<V> callable) throws InterruptedException, ExecutionException { try { final Future<V> future = createFutureIfAbsent(key, callable); return future.get(); } catch (final InterruptedException e) { cache.remove(key); throw e; } catch (final ExecutionException e) { cache.remove(key); throw e; } catch (final RuntimeException e) { cache.remove(key); throw e; } }
Future#get() 方法可能会发生异常,这个时候我们应该将对应的 key 从缓存中移除,并将异常抛出给调用者来处理。
第五, setValueIfAbsent() 方法使得用户可以添加那些还未产生的缓存值,
1 2 3 4 5 6 7 8 public void setValueIfAbsent (final K key, final V value) { createFutureIfAbsent(key, new Callable <V>() { @Override public V call () throws Exception { return value; } }); }
注意,尽管我们需要的是一个实际值,依旧需要通过 Callable 包装,
实践:新的缓存方案 例子一,斐波那契序列求值 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 import java.util.concurrent.Callable;import org.slf4j.Logger;import org.slf4j.LoggerFactory;public class FibonacciExample { private static final Logger LOGGER = LoggerFactory.getLogger(FibonacciExample.class); public static void main (final String[] args) throws Exception { final long index = 12 ; final FibonacciExample example = new FibonacciExample (); final long fn = example.getNumber(index); FibonacciExample.LOGGER.debug("The {}th Fibonacci number is: {}" , index, fn); } private final GenericCacheExample<Long, Long> cache = new GenericCacheExample <>(); public FibonacciExample () { cache.setValueIfAbsent(0L , 1L ); cache.setValueIfAbsent(1L , 1L ); } public long getNumber (final long index) throws Exception { return cache.getValue(index, new Callable <Long>() { @Override public Long call () throws Exception { FibonacciExample.LOGGER.debug("Computing the {} Fibonacci number" , index); return getNumber(index - 1 ) + getNumber(index - 2 ); } }); } }
如上所述,整体改动很小。所有的缓存代码都封装在缓存方案中,只需要简单交互即可,并且不需要考虑线程安全问题,从而可以专注在业务逻辑上。输出结果如下:
1 2 3 4 5 6 7 8 9 10 11 12 Computing the 12 Fibonacci number Computing the 11 Fibonacci number Computing the 10 Fibonacci number Computing the 9 Fibonacci number Computing the 8 Fibonacci number Computing the 7 Fibonacci number Computing the 6 Fibonacci number Computing the 5 Fibonacci number Computing the 4 Fibonacci number Computing the 3 Fibonacci number Computing the 2 Fibonacci number The 12th Fibonacci number is: 233
可以看到,每个序列值只计算了一遍,其他需要用到的时候,都是直接从缓存中获取。
例子二,虚拟的耗时任务 缓存方案并不依赖任何具体类,也就是说可以应用到任何场景中。假设我们有一个虚拟的耗时任务需要缓存:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 import java.util.concurrent.Callable;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import org.springframework.util.StopWatch;public class FictitiousLongRunningTask { private static final Logger LOGGER = LoggerFactory.getLogger(FictitiousLongRunningTask.class); public static void main (final String[] args) throws Exception { final FictitiousLongRunningTask task = new FictitiousLongRunningTask (); final StopWatch stopWatch = new StopWatch ("Fictitious Long Running Task" ); stopWatch.start("First Run" ); task.computeLongTask("a" ); stopWatch.stop(); stopWatch.start("Other Runs" ); for (int i = 0 ; i < 100 ; i++) { task.computeLongTask("a" ); } stopWatch.stop(); FictitiousLongRunningTask.LOGGER.debug("{}" , stopWatch); } private final GenericCacheExample<String, Long> cache = new GenericCacheExample <>(); public long computeLongTask (final String key) throws Exception { return cache.getValue(key, new Callable <Long>() { @Override public Long call () throws Exception { FictitiousLongRunningTask.LOGGER.debug("Computing Fictitious Long Running Task: {}" , key); Thread.sleep(10000 ); return System.currentTimeMillis(); } }); } }
这里使用了 StopWatch 来测量任务在第一次执行完之后从缓存中取出所耗费的时间。同样无需改动缓存方案,只需要简单装配即可。输出如下:
1 2 Computing Fictitious Long Running Task: a StopWatch 'Fictitious Long Running Task': running time (millis) = 10006; [First Run] took 10005 = 100%; [Other Runs] took 1 = 0%
可以看出,一旦第一个任务执行完毕并缓存之后,其他任务几乎可以立马得到预期的结果。
原文地址:http://www.javacreed.com/how-to-cache-results-to-boost-performance/