历法是用年、月、日等时间单位计算时间的方法,现代历法是从古代一步步发展而来的,而且发展颇为曲折,古代人民交通阻塞,交流不便,但是都需要历法来指导农业生产或者活动祭祀,所以各地都独立的发展了自己的历法。西方社会有代表性的就是古希腊历法,古埃及历法和古罗马历法。
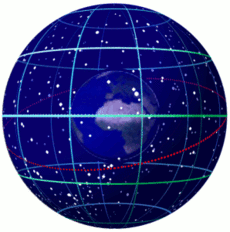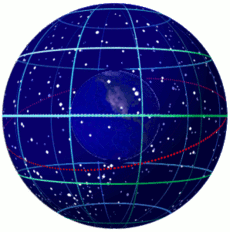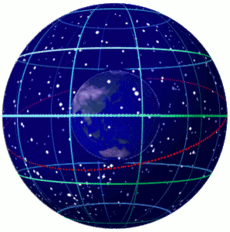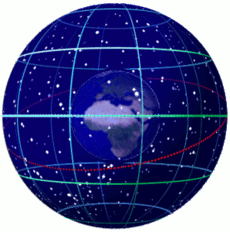
了解历法前,需要了解一点天文学和地理学的知识。我们可以回顾一下托米勒的地心说——地球居于宇宙的中心,太阳以及其他星球围绕地球在各自的轨道上绕地球运动。因此我们可以构造这么一个模型:

地球是一个正球形,围绕一根穿过地球球心(地心)的轴(地轴)旋转,我们虚拟出一个穿过地心并且与地轴垂直的面(“赤道平面”),此平面上方称为北半球,下方称为南半球,北半球与“地轴”的交点称为“北极点”,南半球与“地轴”的交点称为“南极点”,与地球表面的交线称为“赤道”。规定从天空到地球表面的距离都是一样的,太阳在天空表面绕地球运动。因此,从地球上看,天空是一个中空且与地球同球心的正球形,太阳的运行轨道是一个以地心为圆心的一个圆,而且圆上各点都落在天空上,这个圆所在的平面称为“黄道平面”,这个圆就称为“黄道”。
在这个模型中,太阳的运行轨道相对于地轴有一定的夹角(黄赤交角,约23.44°),所以如果我们将“赤道平面”延伸到天空,那么“赤道平面”将会与黄道相交于两个点,这两个点一个是“春分点”一个就是“秋分点”。也因为这个“黄赤交角”的原因,“黄道平面”与“赤道平面”有相同的夹角,所以太阳向南或者向北运行,偏离“赤道平面”的最大角度只能达到“黄赤交角”的大小,也就是说,太阳在地球上的直射点偏离赤道平面的最大角度同样为黄赤交角大小。太阳从南往北到达最大偏角时在黄道上处于的点称为夏至点,太阳从北往南到达最大偏角时在黄道上处于的点称为冬至点,
由于linux上处理word和ppt比较麻烦,而且有文件格式专利的问题,所以以下操作全部在Windows下面进行。
首先需要安装Microsoft Save as PDF加载项,官方下载地址:http://www.microsoft.com/zh-cn/download/details.aspx?id=7
安装成功后可以手工将文档另存为pdf。
需要引用“Win32::OLE”模块
use Win32::OLE;
use Win32::OLE::Const 'Microsoft Word';
use Win32::OLE::Const 'Microsoft PowerPoint';
word转pdf:
sub word2pdf{
my $word_file = $_[0];
my $word = CreateObject Win32::OLE 'Word.Application' or die $!;
$word->{'Visible'} = 0;
my $document = $word->Documents->Open($word_file) || die("Unable to open document ") ;
my $pdffile = $word_file.".pdf";
$document->saveas({FileName=>$pdffile,FileFormat=>wdExportFormatPDF});
$document -> close ({SaveChanges=>wdDoNotSaveChanges});
$word->quit();
}
ppt转pdf
sub ppt2pdf{
my $word_file = $_[0];
my $word = CreateObject Win32::OLE 'PowerPoint.Application' or die $!;
$word->{'Visible'} = 1;
my $document = $word->Presentations->Open($word_file) || die("Unable to open document ") ;
my $pdffile = $word_file.".pdf";
$document->saveas($pdffile,32);
$document -> close ({SaveChanges=>wdDoNotSaveChanges});
$word->quit();
}
W3C和WHATWG这两个当前负责HTML开发的组织对于标准分裂在一定程度上达成了初步共识,意味着未来将有两个版本的HTM5——“snapshot”版本和“living standard”版本。